Apache Hive vs AWS Glue: What are the differences?
Apache Hive: Data Warehouse Software for Reading, Writing, and Managing Large Datasets. Hive facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage; AWS Glue:Fully managed extract, transform, and load (ETL) service. A fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics.
Apache Hive and AWS Glue can be primarily classified as "Big Data" tools.
Some of the features offered by Apache Hive are:
- Built on top of Apache Hadoop
- Tools to enable easy access to data via SQL
- Support for extract/transform/load (ETL), reporting, and data analysis










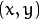 of the destination image, the functions compute coordinates of the corresponding “donor” pixel in the source image and copy the pixel value:
of the destination image, the functions compute coordinates of the corresponding “donor” pixel in the source image and copy the pixel value:
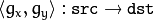 , the OpenCV functions first compute the corresponding inverse mapping
, the OpenCV functions first compute the corresponding inverse mapping  and then use the above formula.
and then use the above formula.









